| New |
 | | Smart Touchless-Touch |
|  Description: Description:
In this project we wish to create a gesture based interaction with a 2D display. The interaction will be based on IVCAM multimodality head pose and hand tracking. By understanding the head’s pose and orientation along with the hand’s location / gesture we get an angle between the two which enables us to understand with which element on the screen the user wishes to interact.
| |  |
|  |
| |
| | 3D Interactions on Standard 2D Displays |
| Description:
In this project we wish to demonstrate how 3D hand tracking and gesture recognition can be used with existing 2D displays to interact in a virtual 3D environment
| | |
| |
|
| | Remote Collaboration |
| Description:
In this project we wish to implement a remote collaboration between two users based on Intel’s user-facing depth camera. During the project the students will need to research for a winning usage for remote collaboration based on close range user facing depth cameras and implement this usage
| | |
| |
| |
| | Surprising Events in Videos |
| Description:
Automatic processing of video data is essential in order to allow efficient access to large amounts of video content, a crucial point in such applications as video mining and surveillance. In this project we will focus on the problem of identifying interesting parts of the video. Specifically, we seek to identify atypical video events, which are the events a human user would naturally look for.
| | |
| |
|
| | Avatar mirrors users facial expressions in real-time |
| Description:
Virtual interactive persons are becoming increasingly common and have implications for gaming, web chats, and for controlling virtual characters at events. The goal of this project is to create an avatar that can mirror your facial expressions in real-time, using a standard webcam to track your face.
| | |
| |
| |
|
| | Content Aware Rotation |
| Description:
Casually shot photos can appear tilted, and are often corrected by rotation and cropping. This trivial solution may remove desired content and hurt image integrity. Instead of doing rigid rotation, we will implement a warping method that creates the perception of rotation and avoids cropping. Human vision studies suggest that the perception of rotation is mainly due to horizontal/vertical lines. We will implement an optimization-based method that preserves the rotation of horizontal/vertical lines, maintains the completeness of the image content, and reduces the warping distortion. An efficient algorithm is developed to address the challenging optimization.
| | |
| |
| |
| | Virtual Rubik's Cube |
| Description:
Many real life problems are complicated enough, but when attempting to solve them using a computer simulation there is the added complexity of manipulating the controls which makes it more difficult and awkward than the original problem already is. Using Natural User Interface (arm motions) we will attempt to create an interface where a virtual Rubi's cube can be manipulated and solved using arm motions. This is an important step in making interaction and problem solving with computers easier.
| | |
| |
|
| | Virtual Solar System |
| Description:
In the process of learning something new, sometimes visualizing it is a key aspect to really understanding. In this project we will create a virtual reality environment where the user can study the solar system and planets in an interactive and visually pleasing way. The user will be able to inspect the model of the solar system from different directions, and with gestures be able to receive specific information from what he sees.
| | |
| |
| |
| | Being in a Virtual World |
| Description:
Using virtual reality glasses allows a user to feel like he’s looking through a window into a virtual world. But when the user moves, the point of view doesn’t change since the glasses don’t include the information about the location of the wearer. In this project we want to use a Kinect camera to track the user location and allow him to move about a virtual room and to feel as if he was really there.
| | |
| |
|
| | Real-World faces in 3D |
| Description:
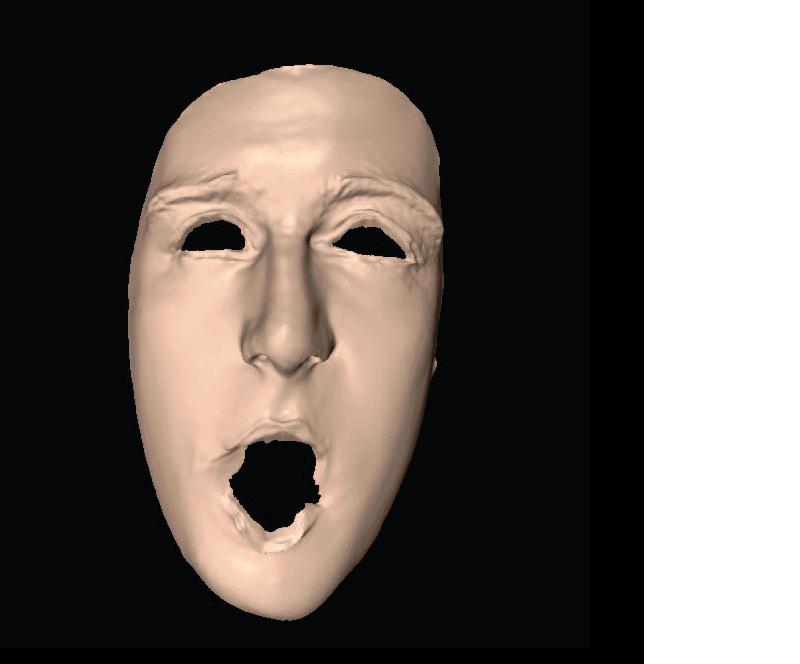
We will build a data-driven method for estimating the 3D shapes of faces viewed in single photo. The method will be designed with an emphasis on robustness and efficiency – with the explicit goal of deployment in real-world applications which reconstruct and display faces in 3D.
| | |
| |
| |
| | Automatic 3D sign language animation |
| Description:
Currently, human Sign Language translators are essential for effective communication between Deaf and hearing presenters and their audiences. Good sign language translators are in high demand and are not always available for extremely short interactions. That means that communication among hearing and Deaf may be impaired or nonexistent, to the detriment of both groups. In the United States sign language is the preferred language for over a 500,000 people
| | |
| |
|
| | Screw Factory |
| Description:
Every handyman knows the feeling when you lost a screw. We will build the solution for such situations. Imagine that you could take a photo of another screw, or even the hole where the screw should fit. From this photo the system will create a 3D model that can be printed. Walla! You have the screw.
| | |
| |
| |
| | 3D Facial Capture Using a KINECT Camera |
| Description:
This project presents an automatic and robust approach that accurately captures high-quality 3D facial performances using a single RGBD camera. The key approach is to combine the power of automatic facial feature detection and image-based 3D nonrigid registration techniques for 3D facial reconstruction.
| | |
| |
|
| | Hand Pose Estimation from Kinect |
| Description:
We will tackle the practical problem of hand pose estimation from a single noisy depth image. A dedicated three-step pipeline will be used: Initial estimation step provides an initial estimation of the hand in-plane orientation and 3D location; Candidate generation step produces a set of 3D pose candidate from the Hough voting space with the help of the rotational invariant depth features; Verification step delivers the final 3D hand pose as the solution to an optimization problem.
| | |
| |
| |
| | Gaze prediction in Egocentric Video |
| Description:
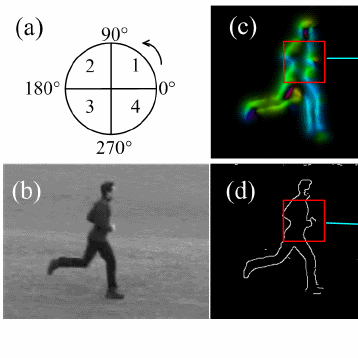
We will implement a model for gaze prediction in egocentric video by leveraging the implicit cues that exist in camera wearer’s behaviors. Specifically, we compute the camera wearer’s head motion and hand location from the video and combine them to estimate where the eyes look.
| | |
| |
|
| | Remember me ! |
| Description:
Contemporary life bombards us with many new images of faces every day, which poses non-trivial constraints on human memory. The vast majority of face photographs are intended to be remembered, either because of personal relevance, commercial interests or because the pictures were deliberately designed to be memorable. Can we make a portrait more memorable or more forgettable automatically?
| | |
| |
| |
| | Deblurring by Example |
| Description:
In this project we will implement a new method for deblurring photos using a sharp reference example that contains some shared content with the blurry photo. Most previous deblurring methods that exploit information from other photos require an accurately registered photo of the same static scene. In contrast, our method aims to exploit reference images where the shared content may have undergone substantial photometric and non-rigid geometric transformations, as these are the kind of reference images most likely to be found in personal photo albums.
| | |
| |
|
|