| | 2017 |
|
|
On Visibility & Empty-Region Graphs,
Sagi Katz and Ayellet Tal.
SMI 2017.
|
 |
 |
Abstract:
Empty-Region graphs are well-studied in Computer Graphics, Geometric Modeling, Computational Geometry, as well as in Robotics and Computer Vision. The vertices of these graphs are points in space, and two vertices are connected by an arc if there exists an empty region of a certain shape and size between them. In most of the graphs discussed in the literature, the empty region is assumed to be a circle or the union/intersection of circles. In this paper we propose a new type of empty-region graphs— the gamma-visibility graph. This graph can accommodate a variety of shapes of empty regions and may be defined in any dimension. Interestingly, we will show that commonly-used shapes are a special case of our graph. In this sense, our graph generalizes some empty-region graphs. Though this paper is mostly theoretical, it may have practical implication—the numerous applications that make use of empty-region graphs would be able to select the best shape that suits the problem at hand.
| |
|
|
 |
| | 2015 |
|
|
On the Visibility of Point Clouds,
Sagi Katz and Ayellet Tal.
ICCV 2015 (ORAL).
|
|
|
Abstract:
Is it possible to determine the visible subset of points directly from a given point cloud? Interestingly, in [7] it was shown that this is indeed the case—despite the fact that points cannot occlude each other, this task can be performed without surface reconstruction or normal estimation. The operator is very simple—it first transforms the points to a new domain and then constructs the convex hull in that domain. Points that lie on the convex hull of the transformed set of points are the images of the visible points. This operator found numerous applications in computer vision, including face reconstruction, keypoint detection, finding the best viewpoints, reduction of points, and many more. The current paper addresses a fundamental question: What properties should a transformation function satisfy, in order to be utilized in this operator? We show that three such properties are sufficient—the sign of the function, monotonicity, and a condition regarding the function’s parameter. The correctness of an algorithm that satisfies these three properties is proved. Finally, we show an interesting application of the operator—assignment of visibility-confidence score. This feature is missing from previous approaches, where a binary yes/no visibility is determined. This score can be utilized in various applications; we illustrate its use in view-dependent curvature estimation.
| |
|
|
|
Solving Multiple Square Jigsaw Puzzles with Missing Pieces,
Genady Paikin and Ayellet Tal.
IEEE Computer Vision and Pattern Recognition (CVPR), 2015.
|
|
|
Abstract:
Jigsaw-puzzle solving is necessary in many applications, including biology, archaeology, and every-day life. In this paper we consider the square jigsaw puzzle problem, where the goal is to reconstruct the image from a set of non-overlapping, unordered, square puzzle parts. Our key contribution is a fast, fully-automatic, and general solver, which assumes no prior knowledge about the original image. It is general in the sense that it can handle puzzles of unknown size, with pieces of unknown orientation, and even puzzles with missing pieces. Moreover, it can handle all the above, given pieces from multiple puzzles. Through an extensive evaluation we show that our approach outperforms state-of-the-art methods on commonly-used datasets. But, it can solve puzzles that none of previous approaches could – those with missing pieces or multiple puzzles whose pieces are mixed together.
| |
|
|
|
| | 2014 |
|
|
3D shape analysis for archaeology,
Ayellet Tal.
3D Research Challenges in Cultural Heritage; Springer Berlin Heidelberg, 2014.
|
|
|
Abstract:
Archaeology is rapidly approaching an impasse in its ability to handle the overwhelming amount and complexity of the data gener- ated by archaeological research. In this paper, we describe some results of our e orts in developing automatic shape analysis techniques for sup- porting several fundamental tasks in archaeology. These tasks include documentation, looking for corollaries, and restoration. We assume that the input to our algorithms is 3D scans of archaeological artifacts. Given these scans, we describe three techniques of documentation, for produc- ing 3D visual descriptions of the scans, which are all non-photorealistic. We then proceed to explain our algorithm for partial similarity of 3D shapes, which can be used to query databases of shape, searching for corollaries. Finally, within restoration, we describe our results for dig- ital completion of broken 3D shapes, for reconstruction of 3D shapes based on their line drawing illustrations, and for restoration of colors on 3D objects. We believe that when digital archaeological reports will spread around the globe and scanned 3D representations replace the 2D ones, our methods will not only accelerate, but also improve the results obtained by the current manual procedures.
| |
|
|
|
How to Evaluate Foreground Maps?,
Ran Margolin, Lihi Zelnik-Manor, Ayellet Tal.
CVPR 2014.
|
|
|
Abstract:
The output of many algorithms in computer-vision is either non-binary maps or binary maps (e.g., salient object detection and object segmentation). Several measures have been suggested to evaluate the accuracy of these foreground maps. In this paper, we show that the most commonly-used measures for evaluating both non-binary maps and binary maps do not always provide a reliable evaluation. This includes the Area-Under-the-Curve measure, the Average- Precision measure, the F -measure, and the evaluation measure of the PASCAL VOC segmentation challenge. We start by identifying three causes of inaccurate evaluation. We then propose a new measure that amends these flaws. An appealing property of our measure is being an intuitive generalization of the F -measure. Finally we propose four meta-measures to compare the adequacy of evaluation measures. We show via experiments that our novel measure is preferable.
| |
|
|
|
| | 2013 |
| | Paper Of The Month |
|
|
Pattern-Driven Colorization of 3D Surfaces,
George Leifman and Ayellet Tal.
CVPR 2013.
|
|
|
Abstract:
Colorization refers to the process of adding color to black & white images or videos. This paper extends the term to handle surfaces in three dimensions. This is important for applications in which the colors of an object need to be restored and no relevant image exists for texturing it. We focus on surfaces with patterns and propose a novel algorithm for adding colors to these surfaces. The user needs only scribble a few color strokes on one instance of each pattern, and the system proceeds to automatically colorize the whole surface. For this scheme to work, we address not only the problem of colorization, but also the problem of pattern detection on surfaces.
| |
|
|
|
SIFTpack: A Compact Representation for Efficient SIFT Matching,
A. Gilinsky and L. Zelnik-Manor.
ICCV 2013.
|
|
|
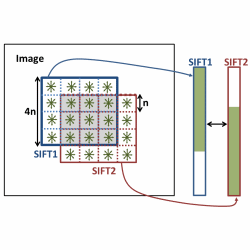
Abstract:
What makes an object salient? Most previous work assert that distintness is the dominating factor. The difference between the various algorithms is in the way they compute distinctness. Some focus on the patterns, others on the colors, and several add high-level cues and priors. We propose a simple, yet powerful, algorithm that integrates these three factors. Our key contribution is a novel and fast approach to compute pattern distinctness. We rely on the inner statistics of the patches in the image for identifying unique patterns. We provide an extensive evaluation and show that our approach outperforms all state-of-the-art methods on the five most commonly-used datasets.
| |
|
|
|
Video Inlays: A System for User-Friendly Matchmove,
D. Rudoy and L. Zelnik-Manor.
VRST 2013.
|
|
|
Abstract:
What makes an object salient? Most previous work assert that distintness is the dominating factor. The difference between the various algorithms is in the way they compute distinctness. Some focus on the patterns, others on the colors, and several add high-level cues and priors. We propose a simple, yet powerful, algorithm that integrates these three factors. Our key contribution is a novel and fast approach to compute pattern distinctness. We rely on the inner statistics of the patches in the image for identifying unique patterns. We provide an extensive evaluation and show that our approach outperforms all state-of-the-art methods on the five most commonly-used datasets.
| |
|
|
|
Learning video saliency from human gaze using candidate selection,
D. Rudoy, D.B Goldman, E. Shechtman and L. Zelnik-Manor.
CVPR 2013.
|
|
|
Abstract:
What makes an object salient? Most previous work assert that distintness is the dominating factor. The difference between the various algorithms is in the way they compute distinctness. Some focus on the patterns, others on the colors, and several add high-level cues and priors. We propose a simple, yet powerful, algorithm that integrates these three factors. Our key contribution is a novel and fast approach to compute pattern distinctness. We rely on the inner statistics of the patches in the image for identifying unique patterns. We provide an extensive evaluation and show that our approach outperforms all state-of-the-art methods on the five most commonly-used datasets.
| |
|
|
|
What Makes a Patch Distinct?,
Ran Margolin, Ayellet Tal, Lihi Zelnik-Manor.
CVPR 2013.
|
|
|
Abstract:
What makes an object salient? Most previous work assert that distintness is the dominating factor. The difference between the various algorithms is in the way they compute distinctness. Some focus on the patterns, others on the colors, and several add high-level cues and priors. We propose a simple, yet powerful, algorithm that integrates these three factors. Our key contribution is a novel and fast approach to compute pattern distinctness. We rely on the inner statistics of the patches in the image for identifying unique patterns. We provide an extensive evaluation and show that our approach outperforms all state-of-the-art methods on the five most commonly-used datasets.
| |
|
|
|
|