|
| |
MeshWalker: Deep Mesh Understanding by Random Walks
 Description: Description:Most attempts to represent 3D shapes for deep learning have focused on volumetric grids, multi-view images and point clouds. In this paper we look at the most popular representation of 3D shapes in computer graphics - a triangular mesh - and ask how it can be utilized within deep learning. The few attempts to answer this question propose to adapt convolutions & pooling to suit Convolutional Neural Networks (CNNs). This paper proposes a very different approach, termed MeshWalker, to learn the shape directly from a given mesh. The key idea is to represent the mesh by random walks along the surface, which "explore" the mesh's geometry and topology. Each walk is organized as a list of vertices, which in some manner imposes regularity on the mesh. The walk is fed into a Recurrent Neural Network (RNN) that "remembers" the history of the walk. We show that our approach achieves state-of-the-art results for two fundamental shape analysis tasks: shape classification and semantic segmentation. Furthermore, even a very small number of examples suffices for learning. This is highly important, since large datasets of meshes are difficult to acquire.
|
|
|
 |
|
| |
Solving Archaeological Puzzles
Description:
Puzzle solving is a difficult problem in its own right, even when the pieces are all square and build up a natural image. But what if these ideal conditions do not hold? One such application domain is archaeology, where restoring an artifact from its fragments is highly important. From the point of view of computer vision, archaeological puzzle solving is very challenging, due to three additional difficulties: the fragments are of general shape; they are abraded, especially at the boundaries (where the strongest cues for matching should exist); and the domain of valid transformations between the pieces is continuous. The key contribution of this paper is a fully-automatic and general algorithm that addresses puzzle solving in this intriguing domain. We show that our state-of-the-art approach manages to correctly reassemble dozens of broken artifacts and frescoes.
|
|
|
|
|
| |
Viewpoint Estimation - Insights & Model
Description:
This paper addresses the problem of viewpoint estimation of an object in a given image. It presents five key insights and a CNN that is based on them. The network's major properties are as follows. (i) The architecture jointly solves detection, classi cation, and viewpoint estimation. (ii) New types of data are added and trained on. (iii) A novel loss function, which takes into account both the geometry of the problem and the new types of data, is propose. Our network allows a substantial boost in performance: from 36.1% gained by SOTA algorithms to 45.9%.
|
|
|
|
|
| |
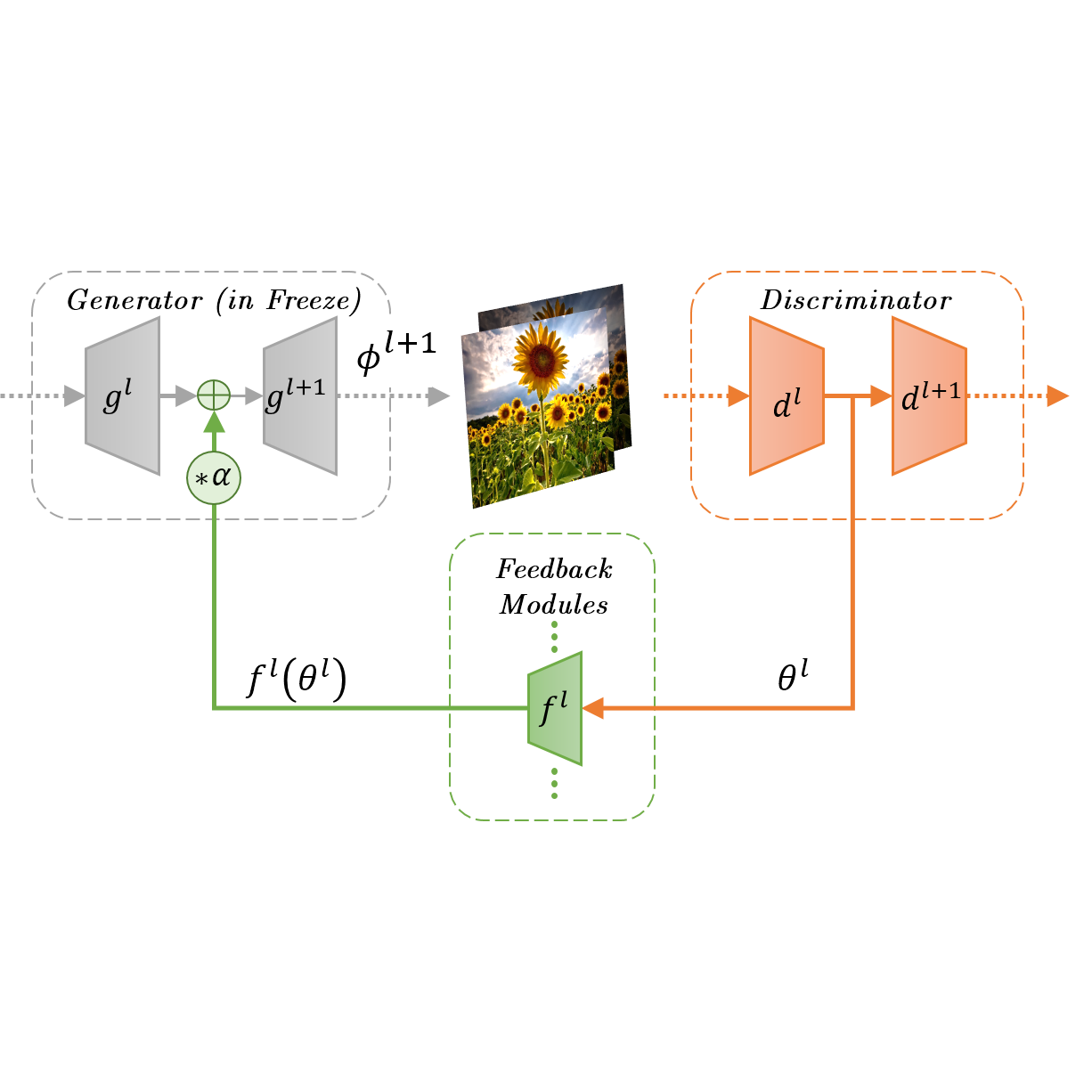
Adversarial Feedback Loop
Description:
Thanks to their remarkable generative capabilities, GANs have gained great popularity, and are used abundantly in state-of-the-art methods and applications. In a GAN based model, a discriminator is trained to learn the real data distribution. To date, it has been used only for training purposes, where it’s utilized to train the generator to provide real-looking outputs. In this paper we propose a novelmethodthatmakesanexplicituseofthediscriminator in test-time, in a feedback manner in order to improve the generator results. Tothe best ofour knowledge itis the ?rst time a discriminator is involved in test-time. We claim that the discriminator holds signi?cant information on the real data distribution, that could be useful for test-time as well, a potential that has not been explored before. Theapproachweproposedoesnotaltertheconventional training stage. At test-time, however, it transfers the output fromthegeneratorintothediscriminator,andusesfeedback modules (convolutional blocks) to translate the features of the discriminator layers into corrections to the features of thegeneratorlayers,whichareusedeventuallytogetabetter generator result. Our method can contribute to both conditional and unconditional GANs. As demonstrated by our experiments, it can improve the results of state-of-theart networks for super-resolution, and image generation.
|
|
|
|
|
| |
Dynamic-Net: Tuning the Objective Without Re-training
Description:
One of the key ingredients for successful optimization of modern CNNs is identifying a suitable objective.
To date, the objective is fixed a-priori at training time, and any variation to it requires re-training a new network.
In this paper we present a first attempt at alleviating the need for re-training. Rather than fixing the network at training time, we train a “Dynamic-Net” that can be modified at inference time.
Our approach considers an “objective-space” as the space of all linear combinations of two objectives, and the Dynamic-Net can traverse this objective-space at test-time, without any further training.
We show that this upgrades pre-trained networks by providing an out-of-learning extension, while maintaining the performance quality.
The solution we propose is fast and allows a user to interactively modify the network, in real-time, in order to obtain the result he/she desires.
We show the benefits of such an approach via several different applications.
|
|
|
|
|
| |
Learning to Maintain Natural Image Statistics
Description:
Maintaining natural image statistics is a crucial factor in restoration and generation of realistic looking images.
When training CNNs, photorealism is usually attempted by adversarial training (GAN), that pushes the output images to lie on the manifold of natural images.
GANs are very powerful, but not perfect. They are hard to train and the results still often suffer from artifacts.
In this paper we propose a complementary approach, whose goal is to train a feed-forward CNN to maintain natural internal statistics.
We look explicitly at the distribution of features in an image and train the network to generate images with natural feature distributions.
Our approach reduces by orders of magnitude the number of images required for training and achieves state-of-the-art results on both single-image super-resolution, and high-resolution surface normal estimation.
|
|
|
|
|
| |
The Contextual Loss for Image Transformation with Non-Aligned Data
Description:
Feed-forward CNNs trained for image transformation problems rely on loss functions that measure the similarity between the generated image and a target image.
Most of the common loss functions assume that these images are spatially aligned and compare pixels at corresponding locations.
However, for many tasks, aligned training pairs of images will not be available. We present an alternative loss function that does not require alignment,
thus providing an effective and simple solution for a new space of problems. Our loss is based on both context and semantics -- it compares regions with similar semantic meaning,
while considering the context of the entire image. Hence, for example, when transferring the style of one face to another, it will translate eyes-to-eyes and mouth-to-mouth.
|
|
|
|
|
| |
Saliency Driven Image Manipulation
Description:
Have you ever taken a picture only to find out that an unimportant background object ended up being overly
salient? Or one of those team sports photos where your favorite player blends with the rest? Wouldn’t it be nice if you
could tweak these pictures just a little bit so that the distractor would be attenuated and your favorite player will
stand-out among her peers? Manipulating images in order to control the saliency of objects is the goal of this paper.
We propose an approach that considers the internal color and saliency properties of the image. It changes the
saliency map via an optimization framework that relies on patch-based manipulation using only patches from within
the same image to maintain its appearance characteristics. Comparing our method to previous ones shows significant
improvement, both in the achieved saliency manipulation and in the realistic appearance of the resulting images.
|
|
|
|
|
| |
Photorealistic Style Transfer with Screened Poisson Equation
Description:
Recent work has shown impressive success in transferring painterly style to images. These approaches, however, fall short of photorealistic style transfer. Even when both the input and reference images are photographs, the output still exhibits distortions reminiscent of a painting. In this paper we propose an approach that takes as input a stylized image and makes it more photorealistic. It relies on the Screened Poisson Equation, maintaining the fidelity of the stylized image while constraining the gradients to those of the original input image. Our method is fast, simple, fully automatic and shows positive progress in making a stylized image photorealistic. Our results exhibit finer details and are less prone to artifacts than the state-of-the-art.
|
|
|
|
|
| |
Template Matching with Deformable Diversity Similarity
Description:
We propose a novel measure for template matching named Deformable Diversity Similarity -- based on the diversity of feature matches between a target image window and the template. We rely on both local appearance and geometric information that jointly lead to a powerful approach for matching. Our key contribution is a similarity measure, that is robust to complex deformations, significant background clutter, and occlusions. Empirical evaluation on the most up-to-date benchmark shows that our method outperforms the current state-of-the-art in its detection accuracy while improving computational complexity.
|
|
|
|
|
| |
Text Documents Binarization
Description:
Given an image containing text, its binarized map classifies each pixel to its origin – being a foreground (text) or background pixel. The Binarization is usually a pre-processing step for Character Recognition tasks. Character Recognition performance.
When considering text documents, different artifacts harm the quality of binarization. These artifacts include stains and spills on the original text, internal text-background contrast variations and different degradations that occur over time.
We propose adapting “The Visibility Analysis for Image Processing” framework for this task. The transformed image is detected for visibility to obtain per-pixel information. This information is later combined with an existing binarization algorithm, and best results are obtained over all competitors in the Document Image Binarization Contest 2016 benchmark.
|
|
|
|
|
| |
OTC: A Novel Local Descriptor for Scene Classification
Description:
Scene classification is the task of determining the scene type in which a photograph was taken. In this paper we present a novel local descriptor suited for such a task: Oriented Texture Curves (OTC). Our descriptor captures the texture of a patch along multiple orientations, while maintaining robustness to illumination changes, geometric distortions and local contrast differences. We show that our descriptor outperforms all state-of-the-art descriptors for scene classification algorithms on the most extensive scene classification benchmark to-date.
|
|
|
|
|
| |
How to Evaluate Foreground Maps ?
Description:
The output of many algorithms in computer-vision is either non-binary maps or binary maps (e.g., salient object detection and object segmentation). Several measures have been suggested to evaluate the accuracy of these foreground maps. In this paper, we show that the most commonly-used measures for evaluating both non-binary maps and binary maps do not always provide a reliable evaluation. This includes the Area-Under-the-Curve measure, the Average-Precision measure, the F-measure, and the evaluation measure of the PASCAL VOC segmentation challenge. We start by identifying three causes of inaccurate evaluation. We then propose a new measure that amends these flaws. An appealing property of our measure is being an intuitive generalization of the F-measure. Finally we propose four meta-measures to compare the adequacy of evaluation measures. We show via experiments that our novel measure is preferable.
|
|
|
|
|
| |
What Makes a Patch Distinct ?
Description:
What makes an object salient? Most previous work assert that distinctness is the dominating factor. The difference between the various algorithms is in the way they compute distinctness. Some focus on the patterns, others on the colors, and several add high-level cues and priors. We propose a simple, yet powerful, algorithm that integrates these three factors. Our key contribution is a novel and fast approach to compute pattern distinctness. We rely on the inner statistics of the patches in the image for identifying unique patterns. We provide an extensive evaluation and show that our approach outperforms all state-of-the-art methods on the five most commonly-used datasets.
|
|
|
|
|
| |
Depth-map Super Resolution from a Single Image
Description:
Inexpensive 3D cameras such as Microsoft Kinect are becoming increasingly available for various low- cost applications. However, the images acquired by these cameras suffer from low spatial resolution as well as inaccurate depth measurements. In the paper "Super resolution by single image", Glasner et al. offer a fast and effective super resolution method for natural images. Their method does not rely on an external database or prior examples but exploits patch redundancy in the original low resolution image. In this project we implement this approach and expand it to depth images.
|
|
|
|
|
| |
Mesh Colorization
Description:
This paper proposes a novel algorithm for colorization of meshes. This is important for applications in which the model needs to be colored by just a handful of colors or when no relevant image exists for texturing the model. For instance, archaeologists argue that the great Roman or Greek statues were full of color in the days of their creation, and traces of the original colors can be found. In this case, our system lets the user scribble some desired colors in various regions of the mesh. Colorization is then formulated as a constrained quadratic optimization problem, which can be readily solved. Special care is taken to avoid color bleeding between regions, through the definition of a new direction field on meshes.
Based on the paper:
|
|
|
|
|
| |
Crowdsourcing Gaze Data Collection
Description:
This project proposes a new type of saliency - context-aware saliency - which aims at detecting the image regions that represent the scene. It presents a detection algorithm that realizes this saliency.
Based on the paper:
|
|
|
|
| |
Saliency Detection
Description:
This project proposes a new type of saliency - context-aware saliency - which aims at detecting the image regions that represent the scene. It presents a detection algorithm that realizes this saliency.
Based on the papers:
|
|
|
|
| |
Icon Scanning
Description:
Undoubtedly, a key feature in the popularity of smartmobile devices is the numerous applications one can install. Frequently, we learn about an application we desire by seeing it on a review site, someone else’s device, or a magazine. A user-friendly way to obtain this particular application could be by taking a snapshot of its corresponding icon and being directed automatically to its download link. Such a solution exists today for QR codes, which can be thought of as icons with a binary pattern. In this paper we extend this to App-icons and propose a complete system for automatic icon-scanning: it first detects the icon in a snapshot and then recognizes it.
Based on the paper:
|
|
|
|
| |
Photogrammetric Texture Mapping using Casual Images
Description:
Texture mapping has been a fundamental problem in computer graphics from its early days. As online image databases have become increasingly accessible, the ability to texture 3D models using casual images has gained more importance. This will facilitate, for example, the task of texturing models of an animal using any of the hundreds of images of this animal found on the Internet, or enabling a naive user to create personal avatars using the user's own images.
Based on the paper:
|
|
|
|
| |
Detecting feature curves on surface
Description:
Curves on objects can convey the inherent features of the shape. This paper defines a new class of view-independent curves, denoted demarcating curves. In a nutshell, demarcating curves are the loci of the ``strongest'' inflections on the surface. Due to their appealing capabilities to extract and emphasize 3D textures, they are applied to artifact illustration in archaeology, where they can serve as a worthy alternative to the expensive, time-consuming, and biased manual depiction currently used.
Based on the papers:
Computer-based, automatic recording and illustration of complex archaeological artifacts,
Ayelet Gilboa, Ayellet Tal, Ilan Shimshoni and Michael Kolomenkin.
|
|
|
|
| |
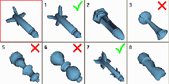
HPR - Simple and fast "Hidden" Point Removal operator
Description:
This paper proposes a simple and fast operator, the "Hidden"
Point Removal operator, which determines the visible points
in a point cloud, as viewed from a given viewpoint.
Visibility is determined without reconstructing a
surface or estimating normals.
Based on the paper:
|
 |
| |
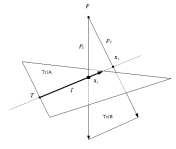
Triangle to Triangle Intersection Test
Description:
A Fast Triangle to Triangle Intersection Test for Collision Detection.
Based on the paper:
|
|
| |
Georgle
Description:
3D models Search engine.
Based on the paper:
|
|
|
| |
|
| | | | | | | | | | | | | | | | |