Accurate Blur Models vs. Image Priors in Super-Resolution
This webpage contains supplementary material for the paper "Accurate Blur Models vs. Image Priors in Super-Resolution" (ICCV 2013).
Netalee Efrat, Daniel Glasner, Alexander Apartsin, Boaz Nadler, Anat Levin
Dept. of Computer Science and Applied Math
The Weizmann Institute of Science,ISRAEL
Paper [PDF] [bibtex]
Abstract
Over the past decade, single image Super-Resolution
(SR) research has focused on developing sophisticated image
priors, leading to significant advances. Estimating and
incorporating the blur model, that relates the high-res and
low-res images, has received much less attention, however.
In particular, the reconstruction constraint, namely that the
blurred and downsampled high-res output should approximately
equal the low-res input image, has been either ignored
or applied with default fixed blur models. In this
work, we examine the relative importance of the image prior
and the reconstruction constraint. First, we show that an
accurate reconstruction constraint combined with a simple
gradient regularization achieves SR results almost as good
as those of state-of-the-art algorithms with sophisticated
image priors. Second, we study both empirically and theoretically
the sensitivity of SR algorithms to the blur model
assumed in the reconstruction constraint. We find that an
accurate blur model is more important than a sophisticated
image prior. Finally, using real camera data, we demonstrate
that the default blur models of various SR algorithms
may differ from the camera blur, typically leading to oversmoothed
results. Our findings highlight the importance
of accurately estimating camera blur in reconstructing raw
low- res images acquired by an actual camera.
We demonstrate the kernel influence using several super-resolution (SR) algorithms on raw images captured by a real camera.
The Algorithms presented here are of [Glasner et al.] and [Yang et al.], as well as sparse prior and bicubic interpolation.
We present for each algorithm two results: i) original default implementation (i.e. )
and ii) after modification to incorporate the camera kernel by imposing the reconstruction constraints with .
For the algorithm of Yang et al. we also retrain the dictionary using examples generated with the camera kernel.
Note that for the sparse prior algorithm there is no "default implementation", the comparison is between using and .
We observe that assuming a bicubic kernel () as done in the default implementation of Yang et al. and of Glasner et al. produces over-smothed results.
[Yang et al.]Yang, J. Wright, T. Huang, and Y. Ma. Image superresolution
via sparse representation. IEEE Trans. Img. Proc.,2010.
[Glasner et al.]Glasner, D. Bagon, S. Irani, M. Super-resolution from a
single image. In ICCV, 2009
To switch between images please use the buttons on the right.
Please note that the magnified images are initialized to bicubic.
Use the scroll bar to view the full extent of the HR images.
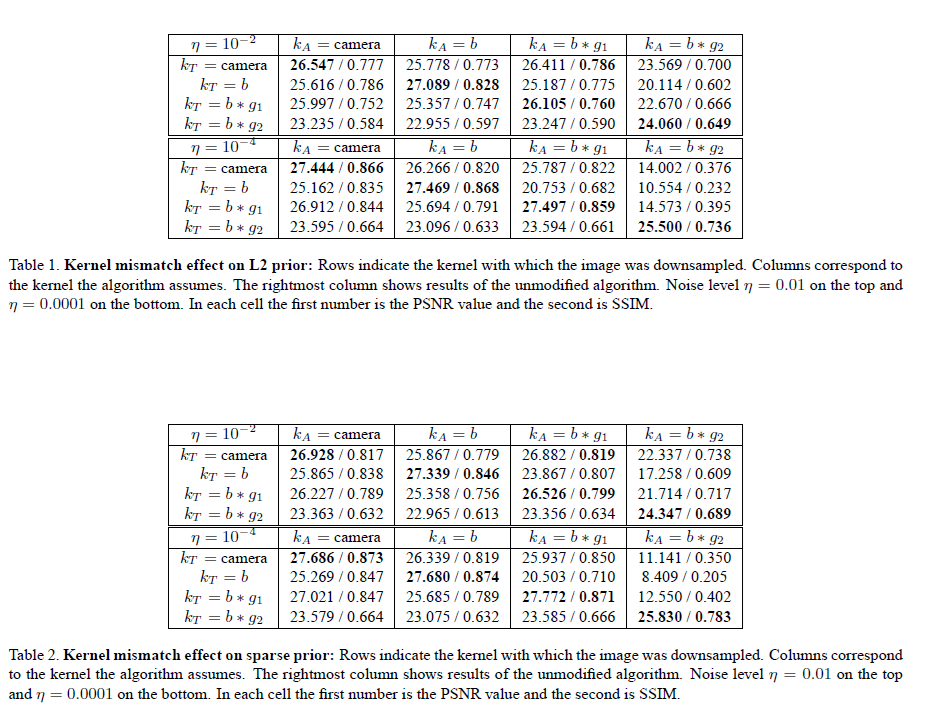
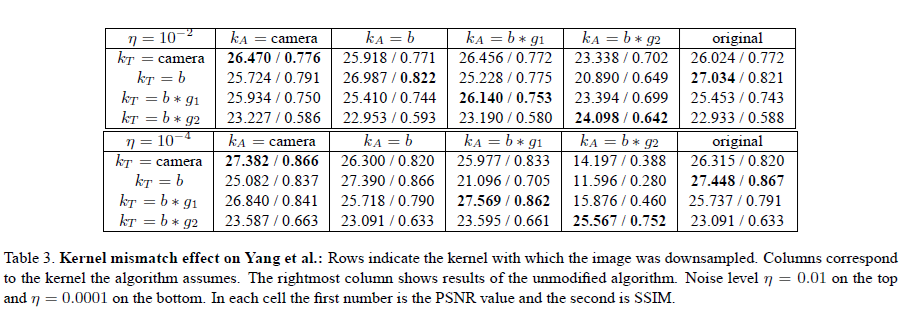
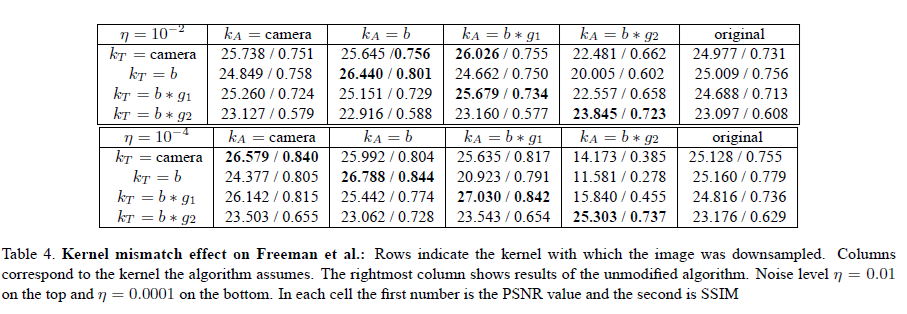
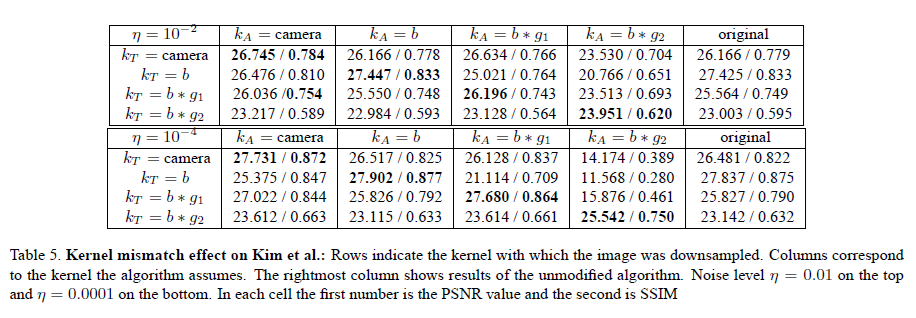
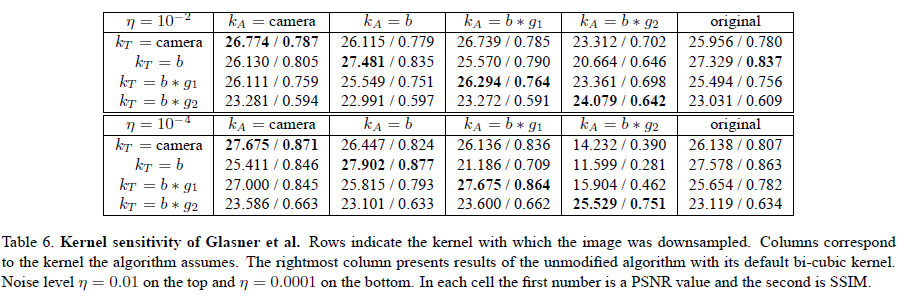
We present quantitative results with 6 different algorithms. In addition to the table showing the results of Glasner et al. which was presented in the paper, we include 5 other tables summarizing results for the algorithms of Yang et al., Freeman et al., Kim et al., and sparse and L2 regularization.
A set of 4 × 5 SR experiments is reported for each algorithm (4 x 4 for the case of sparse and L2 regularization).
SR was applied to the 4 test sets (prepared with different kernels ), each time adjusting the algorithm to
use a different kernel in reconstruction. The fifth column
is the original authors' code which assumes by default a bicubic kernel (except for Freeman et al. which assumes
by default). Where applicable we changed the training data to incorporate knowledge of the kernel.
The algorithms of Yang et al. and of Freeman and Liu were trained using a common training set of LR/HR image pairs, generated using the appropriate blur kernel for each experiment.
We did not modify the training data or the generation of the LR / HR pairs for Kim and Kwon, and for Glasner et al. for which the modification was not straightforward.
We can observe that incorporating the reconstruction constraint with the true kernel (i.e. ) typically
improves the results, and when using the incorrect kernel (i.e. ) the error increases drastically.
[Yang et al.]Yang, J. Wright, T. Huang, and Y. Ma. Image superresolution
via sparse representation. IEEE Trans. Img. Proc.,2010.
[Glasner et al.]Glasner, D. Bagon, S. Irani, M. Super-resolution from a
single image. In ICCV, 2009
[Kim et al.]Kim, K. Kwon, Y. Single-image super-resolution using
sparse regression and natural image prior. PAMI, 2010
[Freeman et al.]Freeman, W. Liu, C. Markov random fields for superresolution
and texture synthesis. Advances in Markov Random Fields for Vision and Image Processing, 2011